スミルノフ・グラブス検定: Smirnov‐Grubbs test
2018/07/31 Last update
このページは Smirnov-Grubbs 検定 @本家UBサイト に恒久的に移転しました。このページもネット上に残っていますが、最新の情報はリンク先を参照して下さい。
- 検定の手順
-
R を使った検定
- Smirnov-Grubbs test(群馬大学)
- Grubbs test(Rパッケージ利用)
- オプション
- 注意事項
関連項目
- 統計の目次
- 外れ値の検定: Outlier test
- ディクソンの外れ値検定: Dixon test
- エラーバーの意味と使い方: Error bar
- 確率変数: Random variable
- 確率密度関数: Probability density function
- 一元配置分散分析: One-way ANOVA
t 検定を理解するために
以下の順に読んで下さい。
- 仮説検定
- z 検定
- t 検定の原理 - 母平均の検定
- 対応のある t 検定
- t 検定メインページ: このページ
- Welch の t 検定: 分散が等しいと言えない場合
- Mann-Whitney の U 検定
- t 分布 t-distribution
- 実践: Excel での t 検定
検定の手順
Smirnov-grubbs test(単に grubbs test という場合もある)は,データが正規分布に従うとき,含まれる外れ値を検出する方法である(1, 3)。
帰無仮説: 全てのデータは同じ母集団からのものである。
対立仮説: データのうち,最大のものは外れ値である。
- 標本の大きさを n,データを X1, X2, ...., Xn とする。
- 平均値を Xm,不偏分散を U とする。
- 最大または最小となる測定値 Xi について,次の式から統計量 Ti を求める。
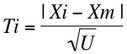
- 統計数値表から,有意点 t を求める。
1. Smirnov-Grubbs test(群馬大学)
R でスミルノフ・グラブス検定をかける方法の一つは,文献1の群馬大学の関数を使わせてもらうことである。ソースは文献1のリンク先にあるが,念のためここにも転載させて頂く。方法を英語にし,コメント部分は改行の関係で一部割愛させて頂いた。
SG <- function(x) # データベクトル
{
method <- "Smirnov-Grubbs test"
data.name <- paste(c("min(", "max("), deparse(substitute(x)), ") = ", range(x, na.rm=TRUE), sep="")
x <- x[!is.na(x)] # 欠損値を除く
n <- length(x) # 標本サイズ
t <- abs(range(x)-mean(x))/sd(x) # 最大・最小データの検定統計量を計算
p <- n*pt(sqrt((n-2)/((n-1)^2/t^2/n-1)), n-2, lower.tail=FALSE) # P 値も2通り計算される
p <- sapply(p, function(p0) min(p0, 1))
result <- list(method=method, parameter=c(df=n-2))
result1 <- structure(c(result, list(data.name=data.name[1], statistic=c(t=t[1]), p.value=p[1])), class="htest")
result2 <- structure(c(result, list(data.name=data.name[2], statistic=c(t=t[2]), p.value=p[2])), class="htest")
return(structure(list(result1, result2), class="SG"))
}
手順としては,
- このスクリプトをコピー&ペーストして実行し,検定のための関数 SG を定義する。
- > source("http://aoki2.si.gunma-u.ac.jp/R/src/SG.R", encoding="euc-jp") としても同じことである(2014年4月12日現在)。
- 外れ値を検出したいデータセットを用意する。方法はデータフレームの作成を参照。データの形式は1次元になるはずである。たとえば,> x=c(1,2,3,4,5,6,7,8,9,100) とすると,1 - 9 と100を要素としてもつデータセット x ができる。
- > SG(x) として,データセットx 中の外れ値を検出できる。結果は以下のようになる。改行などは適宜変更している。
[[1]] Smirnov-Grubbs test
data: min(x) = 1
t = 0.4477, df = 8, p-value = 1
[[2]] Smirnov-Grubbs test
data: max(x) = 100
t = 2.8356, df = 8, p-value = 3.964e-09
2. Rのパッケージを使う方法
R のパッケージを使って Grubbs" test を行う方法もある。こちらの方がスクリプトがシンプルで良さそうである。
> install.packages("outliers") #パッケージ"outliers"のインストール
サーバーを選択し,outliers というパッケージをダウンロードする。成功すると
The downloaded binary packages are in
/var/folders/...省略.../downloaded_packages
というメッセージが出る。次に
> library(outliers)
でこのライブラリーを読み込む。> search() で現在自分が読み込んでいるパッケージの一覧を確認することができる。これが完了したら,上と同様に,1 - 9 と100を要素としてもつデータセット x を作って Grubbs' test を行ってみる。
> x=c(1,2,3,4,5,6,7,8,9,100)
> grubbs.test(x)
結果は
Grubbs test for one outlier
data: x
G = 2.8356, U = 0.0073, p-value = 3.964e-09
alternative hypothesis: highest value 100 is an outlier
となり,100が外れ値であることがわかる。P値が上記の Smirnov-Grubbs test と同じなので,同じ検定をかけているものと思われる。なお,R を再起動したときは > library(outliers) からやらないと関数がみつからないようだ。
注意事項
データフレームの作成の際に,エクセルからのコピーをしたりすると,データが
> x=read.table(pipe("pbpaste"))
> x
V1
1 1
2 2
3 3
4 4
5 5
6 100
References
- スミルノフ・グラブス検定 http://aoki2.si.gunma-u.ac.jp/lecture/Grubbs/Grubbs.html
- Rで外れ値を計算する方法 Web.
- バイオスタティスティクス 外れ値 Web.